
Bodil Nistrup Madsen & Hanne Erdman Thomsen
Note: This article is an abbreviated and revised version of Madsen & Thomsen (2015).
1. Introduction
Concept clarification is vital for the successful development of IT systems and yet this stage is often neglected. Developing a terminological ontology as a basis for the development of a data model gives a solid foundation for the data modelling phases.
This paper shows how we at Copenhagen Business School (CBS) integrate terminological concept modelling as a first step in data modelling. First, we introduce terminological concept modelling with terminological ontologies, i.e. concept systems enriched with characteristics modelled as feature specifications. This enables a formal account of the inheritance of characteristics and allows us to introduce a number of principles and constraints which render terminological concept modelling more coherent than earlier approaches. Second, we explain how terminological ontologies can be used as the basis for developing conceptual and logical data models, and we present the data modelling process developed at CBS comprising four phases: terminological ontology modelling followed by conceptual, logical and physical data modelling. We also show how to map from the various elements in the terminological ontology to elements in the data models, and explain the differences between the models. Finally the usefulness of terminological ontologies as a prerequisite for IT development and data modelling is illustrated with an example from Danish health care. In this way we hope to illustrate that terminological concept modelling forms an important basis for conceptual data modelling, but that the two modelling types differ significantly and should be kept separate.
2. Concept Modelling with Terminological Ontologies
2.1 Basics
Terminology work is concerned with the clarification of concepts and with the linguistic designations used to represent the concepts in communication. According to terminology theory (ISO 704 2009), concepts within a subject field are interrelated and form concept systems. These give a description of the concepts and relationships within the subject field in question (ideally) shared by the community of experts within the field.
In this section, we illustrate terminological concept modelling with terminological ontologies using examples taken from the Danish health care domain. The terminological ontologies show the Danish concepts represented by English glosses, i.e. they are not intended to show the reality nor the terminology of an English speaking environment, and neither are they intended to show elements of a data model. The ontologies are represented in the format provided in the terminology management system i-Term.
Basically, terminological ontologies are concept systems enriched with characteristic features in the form of attribute-value pairs based on Carpenter's "Typed Feature Theory" (Carpenter 1992; Madsen 1998, 339-348; Thomsen 1997, 21-36; Thomsen 1998, 349-359). This is illustrated in Figure 1. Here, each coloured box corresponds to a concept represented by the preferred term, its (known) characteristics are listed below the box, and synonyms and other information (e.g. the definition) can be accessed by double clicking (Figure 1). Lines between concepts correspond to type relations. Other relations may be represented with different line types. The white boxes with text in capital letters represent subdivision criteria.
Carpenter's "Typed Feature Theory" (Carpenter 1992) applies, which means that the characteristics are inherited from a concept to its subordinate concepts, e.g. in Figure 1 the characteristic [DISTRIBUTION: repeated] is inherited from repetitive prescription to its two subordinate concepts. Inheritance implies that a concept can have only one value for a given attribute in order to avoid contradiction. Inheritance of characteristics is the basic principle underlying work with terminological ontologies.
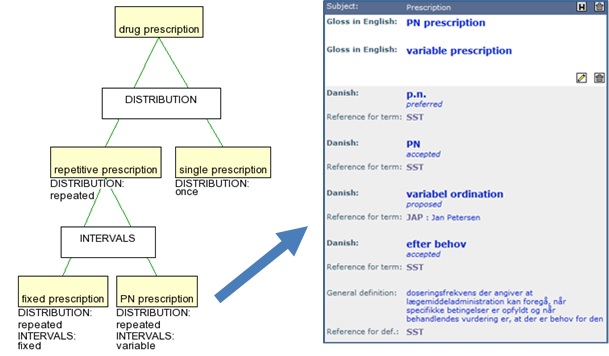
Figure 1. Simple terminological ontology and term base entry
By virtue of inheritance, a given characteristic will be present in several concepts. When it is not inherited, we call it a primary characteristic, so in Figure 1, the characteristic [DISTRIBUTION: repeated] is primary in the concept repetitive prescription, but not in the subordinate concepts. Coordinate concepts (concepts with the same mother or superordinate concept) contain characteristics with the same attribute, but different values. Such attributes are referred to as dimensions. The dimensions are, at the same time, subdivision criteria (see Figure 1).
Terminological ontologies are subject to a number of other principles and constraints (Madsen, Thomsen, and Vikner 2004, 15-19); the most important principles will be explained in the next sections.
2.2 Principle of Uniqueness of Primary Characteristics
The principle of uniqueness of primary characteristics implies that a characteristic can only be used as primary once in a terminological ontology - all other concepts carrying this characteristic must appear in a position subordinate to the concept carrying the primary characteristic. To illustrate this, consider the concept single prescription for saturation, inserted in Figure 2 with the characteristics [DISTRIBUTION: once] and [PURPOSE: achieve a certain level of medication in patient]. This concept must be either subordinate or superordinate to single prescription, in order to comply with this principle, and since it has one characteristic not present in single prescription, it must be subordinate.
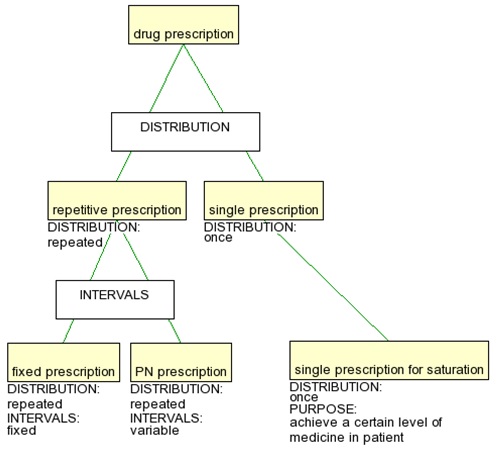
Figure 2. Inclusion of single prescription for saturation
2.3 Principle of Uniqueness of Dimensions
Also dimensions must be unique in a given terminological ontology. This is to ensure that concepts with characteristics sharing an attribute will have a common superordinate. Thus, in Figure 3, the two concepts single prescription for saturation and variable incremental prescription violate this principle since they both have a characteristic with the attribute [PURPOSE], although the values differ.
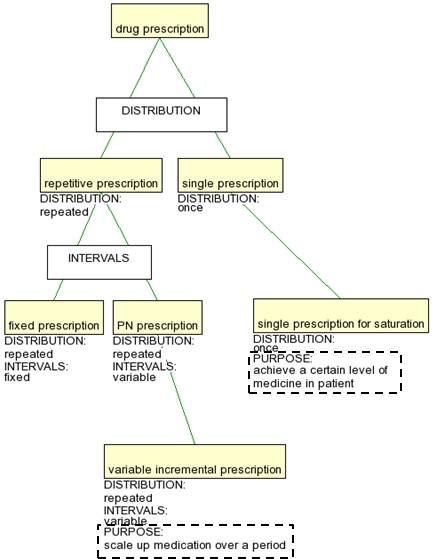
Figure 3. Violation of uniqueness of dimensions
The violation is an indication that the two concepts single prescription for saturation and variable incremental prescription inherit their [PURPOSE] characteristics from two sister concepts to be located elsewhere in the system, and in fact this is so, as illustrated with the circles in the full drug prescription ontology in Figure 4. Note also the associative relation has between the concepts fixed prescription and interval.
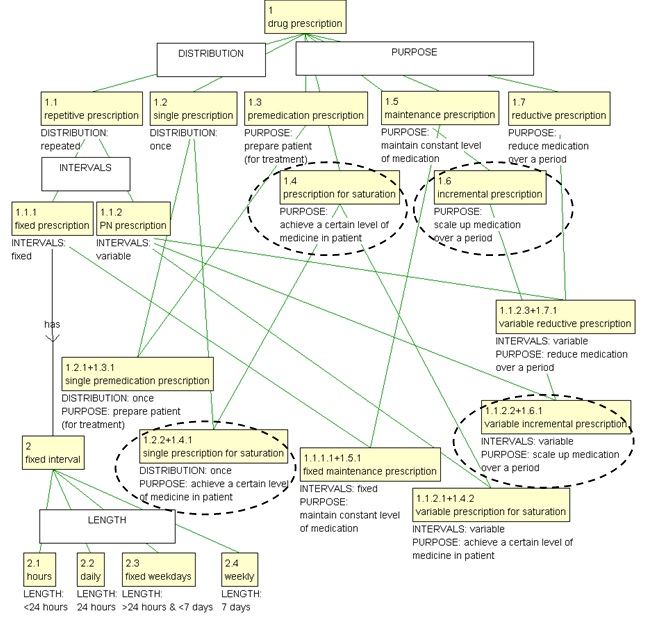
Figure 4. The full drug prescription ontology
2.4 Principle of Grouping by Subdivision Criteria
During the construction of a terminological ontology, several characteristics in a group of coordinate concepts may contain several attributes that are all potential subdivision criteria. The principle of grouping by subdivision criteria states that subdivision criteria should be chosen from the dimensions in such a way that 1) all subordinates are covered and 2) no concept belongs under more than one criterion of subdivision.
A potential violation occurs when the dimensions chosen for sister concepts turn out to overlap as is the case in Figure 5, which illustrates an earlier stage in modelling the drug prescription domain than Figure 4, and here the concept premedication prescription is characterised as a prescription where the patient gets medicine once as a preparation for some treatment (typically before surgery).
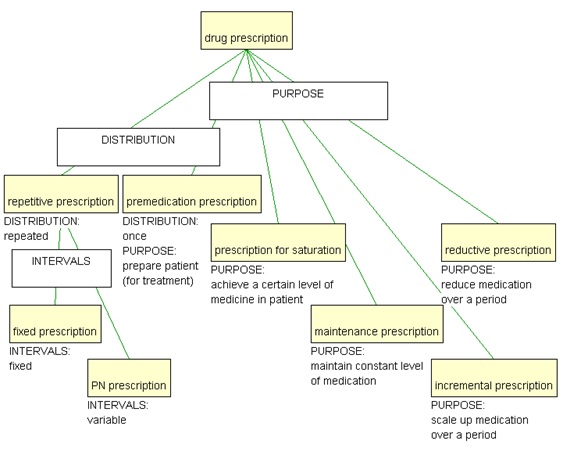
Figure 5. Overlapping subdivision criteria
The violation is an indication that different points of view are being mixed and this should be remedied in order to achieve clarity. In this case, two more concepts are introduced: single prescription and single premedication prescription and now the two dimensions can be isolated, as illustrated in Figure 6, by having the two characteristics on separate concepts and having the concept with both characteristics as a polyhierarchical subordinate to both of these.
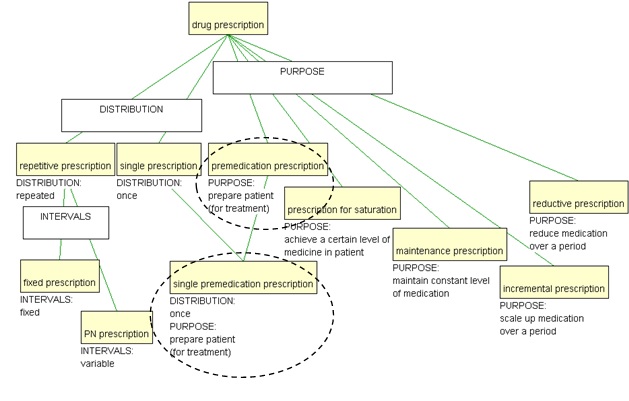
Figure 6. Overlapping criteria eliminated
In fact, at a later stage, not described here, it turned out that there is another subordinate concept to single prescription, since prescription for saturation can be both repetitive and singular, which makes the change described here even more well-founded (Figure 4).
3. Concept Modelling versus Data Modelling
In this section we show how concept clarification by means of a terminological ontology forms a solid foundation for the data modelling process. Terminological ontologies and data models have different aims: ontologies aim at concept clarification, and thus a mutual understanding of concepts and consistent use of terms, whereas data models aim at specifying the types of information to be contained in an IT system and their mutual relationships (Madsen and Thomsen 2009, 239-249; Madsen, Thomsen, and Vikner 2002, 83-88).
Below we present the ideal process of developing the data model for a database application. In the literature, different designations and definitions of the phases can be found. Typically the following three phases are described: conceptual data modelling, logical data modelling and physical data modelling (Hoffer, Prescott, and McFadden 2005; 1keydata.com 2013). However, we find that terminological ontology modelling should be introduced as a new phase prior to the conceptual data modelling. Therefore, the modelling process for developing an IT system that comprises databases, should consist of the four phases presented in Figure 7 (Madsen and Odgaard 2010).
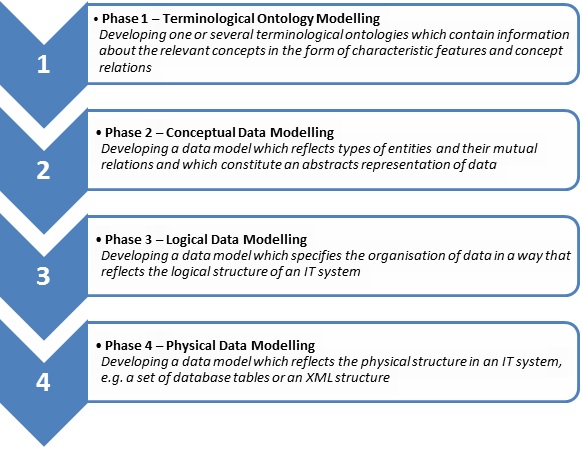
Figure 7. The ideal modelling process
In the following we present the three first modelling phases related to a database for storing information on source references.
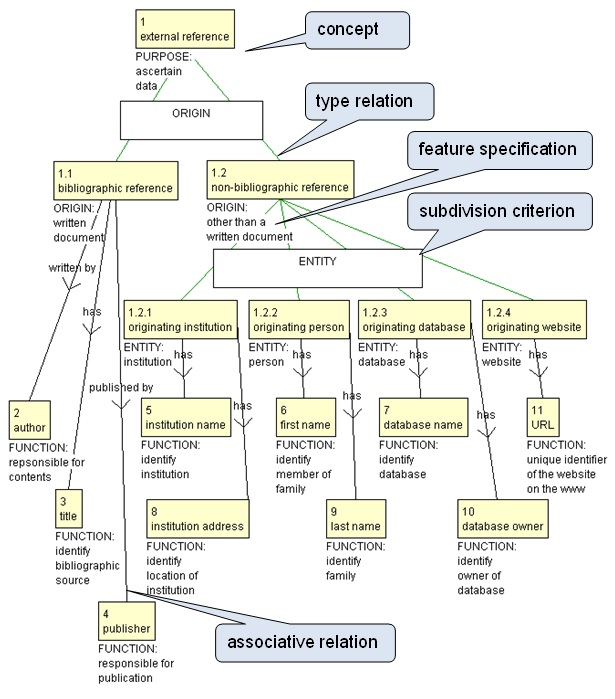
Figure 8. Terminological ontology for source references
Conceptual data models are typically represented by means of diagrams in UML, Unified Modelling Language (OMG 2015), which is a standardised general-purpose modelling language used in object-oriented software engineering. Figure 9 presents a conceptual data model, which has been created on the basis of the terminological ontology in Figure 8. A class (coloured box in Figure 9) represents a number of similar objects, or instances in the database. Associations link classes to each other and thus resemble concept relations in terminology. The association known as specialization (or generalization, depending on the reading direction) is similar to the terminological type relation which can also be read in either direction. Multiplicity indicates the number of objects that participate in the association, e.g. one bibliographical reference may have one or more titles and one title may have one or more bibliographical references (a many-to-many relation).
When moving from a terminological ontology to a conceptual data model, concepts will typically be mapped into classes. Thus, the concepts external reference, bibliographic reference and non-bibliographic reference in Figure 8 have been mapped into classes in Figure 9.
Subdivision criteria in a terminological ontology may be mapped into either classes or discriminators in a conceptual data model. When a subdivision criterion is mapped into a class, the subordinate concepts under the relevant subdivision criterion will then be mapped into attribute values which will eventually become the options of a pick-list in the user interface of the database. Thus, the subdivision criterion [ORIGIN] in Figure 8 is mapped into a class on its own in the conceptual data model in Figure 9, and in the database it may be included as a table comprising values of a pick-list (bibliographic reference and non-bibliographic reference). The usefulness of mapping subdivision criteria into classes is illustrated below.
As mentioned above, a subdivision criterion in a terminological ontology may also be mapped into a discriminator in a conceptual data model. This is illustrated in Figure 9, where the subdivision criterion [ORIGIN] is also mapped into a discriminator.
It is often argued that a conceptual data model is a semantic model and that it aims at concept clarification of the domain of an IT system. However, conceptual data models typically do not supply semantic information about the concepts behind the classes, i.e. they do not comprise characteristics. Definitions or explanations are sometimes given in combination with a conceptual data model, but very often these are actually not definitions, but rather recordings of the purpose of registering some information.
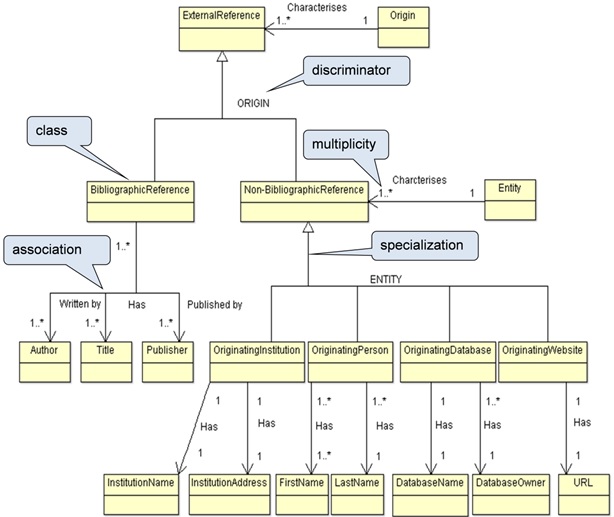
Figure 9. Conceptual data model1
In principle, conceptual data models do not include attributes, although the literature on data models also gives examples of conceptual data models with attributes. Attributes are introduced in the next data modelling phase, i.e. in logical data models (c.f. Figure 10). However, unlike attributes and values in a terminological ontology, attributes in a data model do not define the classes, they merely indicate which kind of information will be related to the instances of the classes, e.g. according to Figure 10, a title will be related to each bibliographic reference in the database and it will be of the data type of this attribute ("String"). Other data types are e.g. "Number", "True/false" (boolean) or "Date" and an initial value may be given, e.g. for a date attribute the initial value may be the current date which will be recorded unless altered by the user.
Conceptual data models are normally quite unspecific, i.e. they rarely include classes representing information types that will later, in the logical data model, be introduced as attributes of classes. However, terminological ontologies often include concepts that will correspond to attributes of the classes in the logical data model or values of attributes in the database tables, which are built on the basis of the logical data model. For example, the terminological ontology in Figure 8 comprises the concepts author, title and publisher. It is our experience from cooperation with public and private organizations, that there is often no consensus on the meaning of general concepts such as author, title and publisher, which in the outset seem to be unproblematic. We therefore propose that such concepts are included in the terminological ontology and mapped into classes in the conceptual data model.
When developing a logical data model, certain simplifications compared to the conceptual data model may be introduced. For example the classes "Author", "Title" and "Publisher" have been introduced as attributes in Figure 10 despite of the many-to-many relations between these classes and the class "BibliographicReference". This means that for example the name of an author will be repeated if there are several bibliographic references with the same author in the database. Here, we will not discuss possible implementations of a conceptual data model into a logical data model.
Terminological ontologies may include concepts that are necessary for concept clarification, but will not be mapped to classes or attributes in the conceptual or logical data model. For example, the terminological ontology in Figure 8 could have included a concept reference as superordinate concept to external reference and internal reference. This concept would not be included as a class in the conceptual data model in Figure 9, because the database will comprise neither a class nor an attribute corresponding to this concept. Of course, there are many ways of setting up a conceptual data model and sometimes a conceptual data model may be very similar to a terminological ontology, i.e. there will be a high degree of one-to-one mapping between concepts and classes.
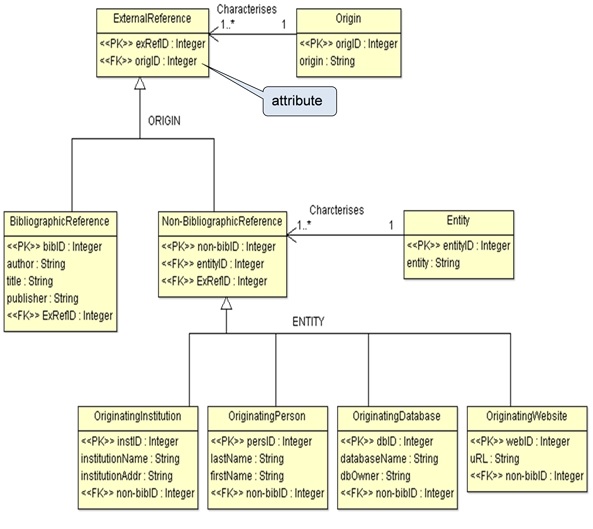
Figure 10. Logical data model
Based on the logical data model in Figure 10, one may develop a physical data model e.g. in the form of a relational database schema, showing the tables of a relational database.
By closely examining the similarities between terminological concept modelling and conceptual data modelling, it is possible to set up guidelines for creating data models on the basis of terminological ontologies. In Madsen and Odgaard (2010) we go one step further and introduce the first attempts at constructing an algorithm for automatically generating conceptual data models on the basis of terminological ontologies.
4. Concept Clarification as a Prerequisite for Digitisation
It is our experience from cooperation with Danish authorities that developing a terminological ontology gives a solid foundation for the development of IT systems or data exchange formats. In this section we present an example from the medical domain.
Figure 11 presents a part of a user interface for a drug prescription system, which was proposed by IT developers for use in a hospital. If the data model behind the user interface had been based on the terminological ontology in Figure 12, the subdivision criteria, [DISTRIBUTION] and [PURPOSE], would have indicated a more logical ordering, i.e. that options 1-3 are related to [DISTRIBUTION], while options 4-6 are related to [PURPOSE]. This is an example of the usefulness of mapping subdivision criteria into classes in the conceptual data model, c.f. above. In this example, it would result in two pick-lists, each with their set of values corresponding to the subordinate concepts under the relevant subdivision criterion. Furthermore, the interface could have illustrated that fixed prescription and PN prescription are types of repetitive prescription as opposed to single prescription, but since you can only select one of them this is of less importance.
The person in charge of the prescription has six different options. However, if we compare the user interface with the simplified terminological ontology in Figure 12, it becomes clear that the fourth option comprises two prescription types: incremental prescription and reductive prescription, which are opposites that should be found as two options in the user interface. Another serious problem is that maintenance prescription, which is the counterpart to prescription for saturation, is missing in the user interface (c.f. Figure 12).

Figure 11. Drug prescription user interface
The information on polyhierarchy, which is presented in the more comprehensive version of the drug prescription ontology in Figure 4, can be used for development of a new user interface allowing for combinations of types of prescription from the two groups under [DISTRIBUTION] and [PURPOSE] (Figure 13). Here, if the user chooses PN prescription, a drop-down menu with the three possible combinations shows, corresponding to the subordinate concepts of PN prescription in Figure 4.
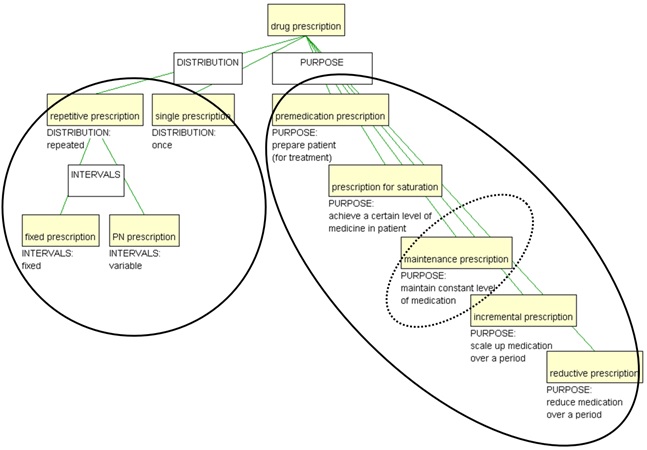
Figure 12. Simplified terminological ontology for drug prescription
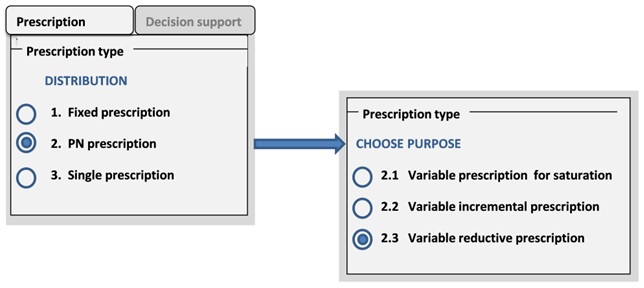
Figure 13. New user interface based on the terminological ontology
5. Conclusion
We hope to have illustrated how terminological concept modelling differs from conceptual data modelling, while, at the same time, to have demonstrated, how the terminological concept clarification is a first valuable step in a data modelling process.
Concept clarification by means of terminological working methods is not a trivial task. By representing concept systems as terminological ontologies with feature specifications and subdivision criteria and by adhering to the principles described here, this task becomes more structured and principled.
1The UML diagrams in this section have been produced with ArgoUML.
- 1keydata.com 2013. "Data Modeling - Conceptual, Logical, And Physical Data Models. In: Data Modeling. Accessed January 13, 2013 (cited 12/01 2015).
- Carpenter, Bob 1992. The Logic of Typed Feature Structures. Cambridge: Cambridge University Press.
- Hoffer, Jeffrey A., Mary B. Prescott & Fred R. Mcfadden 2005.Modern Database Management. Upper Saddle River, New Jersey: Pearson Education.
- ISO 704, 2009. Terminology work - Principles and methods. Geneva: International Standards Organisation.
- Madsen, Bodil Nistrup 1998. "Typed Feature Structures for Terminology Work – Part 1". In: Lita Lundquist, Heribert Picht & Jacques Qvistgaard (eds). LSP - Identity and Interface - Research, Knowledge and Society. Proceedings of the 11th European Symposium on Language for Special Purposes, 339–348. Copenhagen Business School.
- Madsen, Bodil Nistrup & Anna Elisabeth Odgaard 2010. "From Concept Models to Conceptual Data Models." In: Una Bhreathnach & Fionnuala De Barra-Cusack (eds). Terminology and Knowledge Engineering Conference 2010 - Proceedings, 537–544. Dublin: Fiontar.
- Madsen, Bodil Nistrup & Hanne Erdman Thomsen 2009. "Terminological concept modelling and conceptual data modelling". In: International Journal Metadata, Semantics and Ontologies, vol. 4, no. 4, 239–249. Inderscience Enterprises Ltd.
- Madsen, Bodil Nistrup, Hanne Erdman Thomsen, & Carl Vikner 2004. "Principles of a System for Terminological Concept Modelling." In: Maria Teresa Lino, Maria Fransisca Xavier, Fátima Ferreira, Rute Costa & Raquel Silva (eds.). Proceedings of the Fourth International Conference on Language Resources and Evaluation, 15–19. European Language Resources Association (ELRA).
- Madsen, Bodil Nistrup & Hanne Erdman Thomsen 2015. "Concept modeling vs. data modeling in practice." In: Hendrik J. Kockaert & Frieda Steurs (eds.). Handbook of terminology, vol. 1, 250–275. Amsterdam/Philadelphia: John Benjamins Publishing Company.
- OMG 2015. Unified modeling language™ (UML®) resource page. In: OMG - the Object Management Group (database online). (Cited 12/01 2015).
Thomsen, Hanne Erdman 1997. "Feature Specifications Applied to the Field of Life Insurance." In: Terminology Science and Research - Journal of the International Institute for Terminology Research 8(1/2):21–36.
Thomsen, Hanne Erdman 1998. "Typed Feature Structures for Terminology Work - Part II." In: Lita Lundquist, Heribert Picht & Jacques Qvistgaard (eds). LSP - Identity and Interface - Research, Knowledge and Society. Proceedings of the 11th European Symposium on Language for Special Purposes, 349–359. Copenhagen Business School.
About the authors:
Bodil Nistrup Madsen is Professor at the Department of International Business Communication at the Copenhagen Business School.
Hanne Erdman Thomsen is Lecturer at the Department of International Business Communication at the Copenhagen Business School.
 Facebook
Facebook LinkedIn
LinkedIn Twitter
Twitter